RDP 2021-05: Central Bank Communication: One Size Does Not Fit All 6. The Models
May 2021
- Download the Paper 2,051KB
We have 4 different datasets to model: readability for economists, reasoning for economists, readability for non-economists and reasoning for economists. Consequently we develop 4 separate models.
6.1 ML algorithms
There are a number of popular ML algorithms, each with their own strengths and weaknesses. To choose our preferred algorithm we first tested a number of popular ML algorithms on the sub-sample of economist data. These algorithms included the generalised linear model (GLM), the elastic net generalised linear model (GLMNET), the support vector machine (SVM), the gradient boost machine (GBM), and the random forest (RF). We chose to use the RF algorithm because it performed the best in our sub-sample testing and because it is relatively robust to overfitting.
RF is a tree-based algorithm that predicts the classification of data by combining the results from a large number of decision trees (the forest part of its name). A decision tree is a flowchart-like structure that separates samples into 2 categories based on a sequence of yes/no decisions. To construct an individual decision tree, the algorithm first searches over all available variables and selects the variable that provides the best separation of the 2 categories as the top node. It then moves to the next layer and repeats the process to find the variables that give the best separation. The splitting stops when no further improvement can be made (Quinlan 1986). The RF algorithm builds its individual trees independently using a random sub-sample of the data and variables (the random part of its name).
6.2 Model training
In this project, to protect against overfitting, we randomly choose 75 per cent of our data as the training dataset to build the models and use the remaining 25 per cent as the validation dataset for testing model performance. A few approaches were used to improve model performance. First, we adopt an automatic feature selection method that selects the most relevant features for our model; including too many features may lead to overfitting. Second, the RF algorithm has many hyperparameters[18] that affect model performance and we tune these parameters using a grid search approach. Please refer to Appendix C for details about the feature selection and parameter tuning processes.
As our models return a probability prediction (pi)[19], we convert pi to a predicted class label using a threshold. We use the default value of 0.5,[20] so the prediction label for a paragraph is high if pi 0.5 and low otherwise.
We evaluate model performance using 2 standard evaluation metrics: the confusion matrix and the ROC-AUC curve. A confusion matrix is a 2-by-2 table that is calculated by comparing the predicted labels with the actual labels from the validation dataset. The ROC-AUC curve yields a measure of how well the model separates the two classes of data.
For our models, the accuracy (calculated from the confusion matrix as the proportion of labels that are correctly predicted) is around 70 per cent. The AUC ranges from 0.55 to 0.6 for our models. We report the full test results in Appendix D. Overall these results are modest, our model has reasonable accuracy in predicting whether a paragraph is more likely to be high quality than not, but does not yield definitive predictions about paragraph quality. Given that there is an inherent fuzziness to paragraph quality, we think it unsurprising that our algorithm can not cleanly separate high-quality paragraphs from low-quality paragraphs – we suspect humans would struggle to do so as well.
6.3 Feature importance
ML models are often considered to be ‘black boxes’ for their complex inner workings and plethora of opaque parameters. Our dataset has hundreds of features and it is often difficult to understand which features are driving the prediction accuracy of our models. One benefit of the RF algorithm, however, is that it has a built-in function that calculates the contribution of each feature.[21] This helps to discern some of the inner workings of the black box. However, we must emphasise that the underlying models are nonlinear and complex, so one should not over-interpret the results presented here – they are meant to give a heuristic impression about the models. They are not a precise linear representation of the workings of the model in the manner of linear regression coefficients.
Figure 10 illustrates the top 5 features for the readability models, and Figure 11 shows them for the reasoning models. These top features are ranked based on how much information each variable contains to discriminate between the 2 categories.[22]
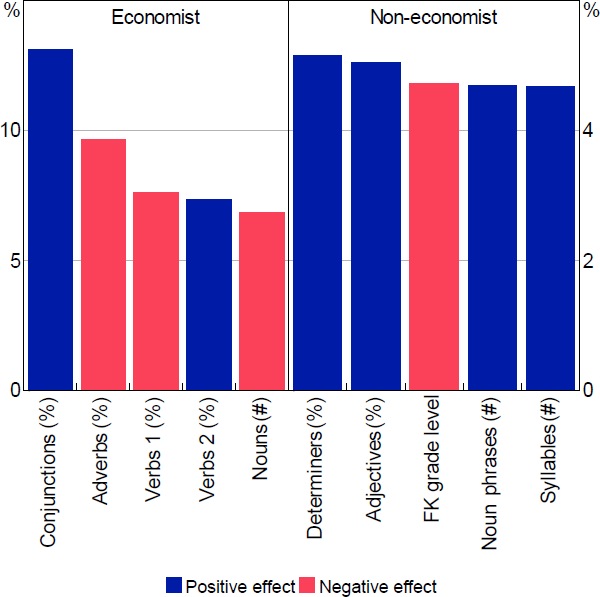
Note: ‘Conjunctions’ refers to coordinating conjunctions, ‘Verbs 1’ refers to all verbs, ‘Verbs 2’ refers to non-third person singular present verbs
Source: Authors' calculations using survey results
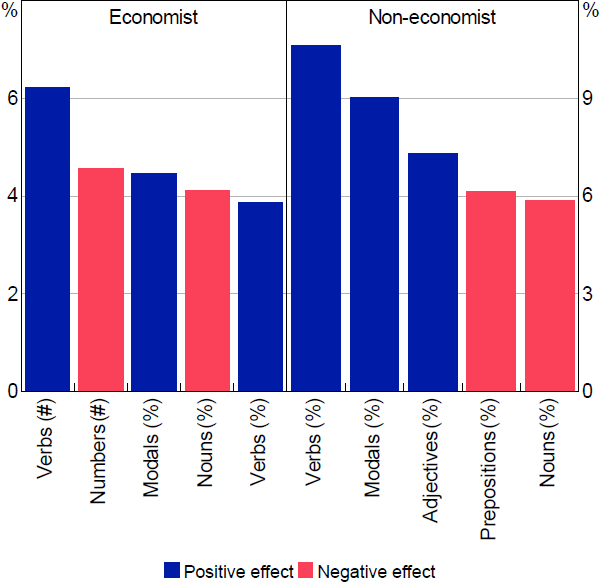
Note: ‘Prepositions’ refers to preposition or subordinating conjunction
Source: Authors' calculations using survey results
It is not typically possible to determine whether the effect of these variables on the results are positive or negative. This is because RF models are capturing complex nonlinear relationships in the data. Notwithstanding this, we can get an idea of whether the average effect of a particular variable is positive or negative. To calculate this we run the models for a sample of 1,424 paragraphs and remove the top 5 variables one by one and regenerate the model prediction. Based on the difference between the 2 results, we classify the partial effect of a variable as positive or negative.[23] There are some similarities in the top features list between the 2 reasoning models but surprisingly little across the readability models.
Looking at the readability models first, we see that the FK grade level appears in the top 5 features for the non-economist model. However, the number of syllables, which contributes to the FK grade level negatively, appears with a positive sign. More generally, the model suggests that non-economists prefer paragraphs with more noun phrases, adjectives and determiners. Conversely, simple metrics don't show up in the economist model. The top feature is the proportion of coordinating conjunctions[24] and there seems to be a preference for paragraphs with fewer nouns and adverbs. One possible explanation for this difference is that economists hold more economic knowledge and, thus, may rely less on linguistic clues in the paragraphs (such as adjectives and determiners) to understand the importance of and relationships between concepts. As noted by Gilliland (cited in Janan and Wray (2012, p 1)):
… in a scientific article, complex technical terms may be necessary to describe certain concepts. A knowledge of the subject will make it easier for a reader to cope with these terms and they, in turn, may help him to sort out his ideas, thus making the text more readable. This interaction between vocabulary and content will affect the extent to which some people can read the text with ease.
There is more similarity in the reasoning models. In particular, both economists and non-economists identify more verbs and fewer nouns with higher reasoning. This is natural because the verb phrase generally denotes eventualities, processes and states, and the roles that participants play in the events described (McRae, Ferretti and Amyote 1997). That is, the kind of terms you would use when expressing an argument or point of view rather than presenting facts. In addition, modal words, such as might, could, and should, are also important for both reasoning models. Modal words are normally associated with persuasive writing, and are often treated as an arguing feature in the study of linguistics (Farra, Somasundaran and Burstein 2015).
These findings are not too surprising but it is worth noting that in preliminary work we tried just using word lists to identify whether an argument was being made (e.g. counting uses of words like ‘because’) and this approach was relatively unsuccessful. That is, we have found that understanding the grammatical function of a word is more valuable in classifying text than the particular word that is used. Or, more poetically, and in the timeless words of Led Zeppelin, using word lists is more error-prone ‘Cause you know sometimes words have two meanings’.
To help gain a greater sense of how the model works in practice, Table 3 presents 2 sample paragraphs, one rated high and one rated low, for each model.
| Model | Paragraph | Model prediction label(a) | Survey scores(b) |
|---|---|---|---|
| Economist– Reasoning | The big question is whether we should expect these quirks to endure. Once a way to make above-market returns is identified, it ought to be harder to exploit. ‘Large pools of opportunistic capital tend to move the market toward greater efficiency,’ say Messrs White and Haghani. For all their flaws and behavioural quirks, people might be capable of learning from their costliest mistakes. The rapid growth of index funds, in which investors settle for an average return by holding all the market's leading stocks, suggests as much. | High (0.90) |
4.5 (1.01) |
| Most of the sectors that declined as a share of non-mining output were capital intense. Agriculture, forestry and fishing, electricity, gas, water and waste services, information, media and telecommunications, and rental, hiring and real estate services declined by nearly 3.5 percentage points of non-mining output. Manufacturing declined by almost ten percentage points of non-mining output. | Low (0.27) |
2.0 (−0.91) |
|
| Economist− Readability | While household dwelling investment continued to decline over the first half of the year, there have been signs in recent months of a prospective improvement, partly in response to reductions in interest rates. Private residential building approvals, dwelling prices and auction clearance rates have all increased. The overall demand for housing finance has been broadly stable over the course of the year and many home owners are taking advantage of lower borrowing rates to pay off their loans more quickly. | High (0.90) |
4.5 (1.35) |
| In any event, there is no strong economic rationale for a different tax rate for small companies. While compliance costs are higher for small companies (relative to their profits), it makes little sense to compensate them via a differentiated tax system. A lower tax rate compensates small companies with high profits much more than those with lower profits, for instance, even though the relative compliance costs are larger for companies with lower profits. The Government should ensure that the small and large company tax rate is equalised over the next few years. | Low (0.39) |
2.0 (−1.58) |
|
| Non-economist– Reasoning | But current planning rules make it hard to build homes in the inner and middle-ring suburbs of our major cities. Recent US studies estimate that GDP would be between 2 per cent and 13 per cent higher if enough housing had been built in cities with strong jobs growth such as New York and San Francisco. If planning rules push people to live on the edge of cities, then this will also push some employers to the edge who would prefer on commercial grounds to locate elsewhere. Influencing business decisions in this way is likely to lead to lower productivity. | High (0.87) |
4.0 (0.71) |
| The price of copper has declined by 13 per cent since its peak in February this year, broadly in line with declines in the prices of other base metals. These price falls occurred alongside expectations for a slowdown in the global economy, including in China. | Low (0.16) |
1.0 (−1.32) |
|
| Non-economist– Readability | In 2017, Australia's net foreign currency asset position amounted to 45 per cent of GDP (ABS 2017b). Around two-thirds of Australia's foreign liabilities were denominated in Australian dollars, compared with around 15 per cent of Australia's foreign assets. Since 2013, foreign currency assets and liabilities have both increased as a share of GDP. Since the dollar increase in assets has been greater than that in liabilities, there has been an increase in Australia's net foreign currency asset position of around 15 percentage points of GDP. | High (0.70) |
4.5 (1.05) |
| Looking at more detailed data on cross-border bank lending from the Bank for International Settlements, it is evident that cross-border lending by European banks both increased most rapidly going into the crisis and subsequently contracted most sharply. Given that financial stress was concentrated in industrialised economies it is also noteworthy that lending to other industrialised economies peaked earlier than lending to emerging markets, which was curtailed only much later into the financial turbulence. This pattern is also evident in the sharp reversal of (net) flows between the United States and the United Kingdom as a result of reduced cross-border lending by European banks headquartered in London as institutions sought to unwind their exposures. | Low (0.28) |
2.0 (−0.83) |
|
Notes:
|
|||
Overall, given that many of the identified features appear to make sense linguistically, at least based on our knowledge and brief reading of the linguistic literature, we are fairly confident that our model has identified meaningful features rather than latched on to idiosyncratic features that have little true explanatory power. A key observation is that, because each model emphasises different features, making paragraphs readable for both economists and non-economists is not simple. For example, the correlation between predicted readability for economists and non-economists is 0.54 in our sample. While there is some correlation it is not straightforward and one size does not fit all. That said, simple metrics such as the FK grade level don't seem to be a good guide to readability. They have little correlation for the non-economist readability model and none at all for the economist model. This implies that targeting a particular FK grade level is unlikely to improve readability for either group.
Footnotes
For instance, ntree and mtry are 2 important parameters for the RF algorithm. ntree represents the number of trees that will be built and mtry is the number of variables that will be randomly sampled for each node in a tree. [18]
In tree-based algorithms, the probability is calculated as the proportion of trees assigning a label of high to a given paragraph. For example, if there are 500 trees in an RF model and 300 of them rate an observation as ‘high,’ it returns a probability of 0.6. [19]
There are other ways to set the threshold and, if the data set is unbalanced – with more of one label than the other – the default 0.5 may not be a good threshold. For this study, 0.5 is a reasonable threshold as our datasets are roughly balanced (for the readability model, 264 paragraphs are labelled as high and 241 as low; for the reasoning model, 248 paragraphs are labelled as high while 251 are labelled as low). [20]
The feature importance is extracted as a part of model outputs that is generated using the caret package in R. The importance value for each variable is calculated as the contribution of each variable based on the mean decrease in impurity (Gini) after removing this feature. Another way to calculate the feature importance is based on the mean decrease of accuracy. [21]
The exact ranking for each variable may vary with different settings of parameters. However, the lists of top 5 variables for the models in this study are relatively stable based on our experiments. [22]
The partial effect of a variable on the target variable is positive if the prediction probability for ‘high’ is lower after removing this variable, and otherwise negative. We should not draw a conclusion on the effect of each feature on the final prediction results as the relationship between a feature and the output from the RF model is often nonlinear. [23]
A coordinating conjunction is a word that joins two parts of a sentence. According to the ‘Part-of-Speech Tagging Guidelines for the Penn Treebank Project’ (Santorini 1990), the coordinating conjunction list includes and, but, nor, or, yet, as well as the mathematical operators plus, minus, less, times (in the sense of ‘multiplied by’) and over (in the sense of ‘divided by’), when they are spelled out. The proportion of coordinating conjunctions is also an important feature for both readability and reasoning models of non-economists. As shown in Table C2, this features ranks seventh for the non-economist readability model and tenth for the reasoning model. [24]