RDP 2021-05: Central Bank Communication: One Size Does Not Fit All 5. Methodology and Model Data
May 2021
- Download the Paper 2,051KB
While the descriptive analysis above has highlighted a number of interesting features of economic communication, more insights can be gained through the application of machine learning (ML) algorithms. In particular, training an ML model to classify paragraphs will allow us to consider a much larger range of paragraphs – and gain insights from them – than we could through the survey alone. A second benefit is that, by observing which features the ML algorithm uses to predict paragraph scores, we can better understand some of the features that make for a higher quality paragraph of economic communication.
5.1 Introduction to ML
While machine learning has become quite popular in recent years, there is a lot of overlap between ML techniques and traditional statistical and econometric techniques. For example, one of the most fundamental ML techniques is regression analysis, particularly logistic regression, which has long been used in more traditional statistical and econometric areas. In its basic form, logistic regression is used to classify data, based on a range of observable variables, into one of two categories. An example might be predicting whether someone will buy a house in a given year based on attributes such as their age, income, job, sex, relationship status and so on. Machine learning, however, generally approaches problems in different ways and, consequently, asks slightly different questions than those commonly tackled by econometrics.
A common, though not universal, quality of ML problems is that there may be limited theory to guide the selection of appropriate explanatory variables, or features as they are called in ML models. Thus, they rely on big data and the associated techniques to learn underlying patterns that can then be used to predict other data rather than relying on theory in the way that more traditional statistics or econometrics tends to. As we have very limited existing theory that can guide us in selecting the set of features that will predict communication quality, we rely on ML techniques in this paper.
Within the field of ML there are a wide variety of techniques. At a high level, these techniques can be divided between supervised and unsupervised ML. In supervised ML the analysis starts with data that has previously been classified and labelled by experts and uses that data to ‘learn’ the basis for that classification. Unsupervised ML, such as cluster analysis, starts with unlabelled data and attempts to infer the underlying structure by identifying patterns. This study uses supervised ML techniques to build models that predict text quality based on the classifications provided by our survey respondents. Given our choice of this technique, there are 2 key elements to our approach that we discuss next: how we choose the labels for paragraphs, and how we convert the text into numerical data amenable to analysis.
5.2 Label paragraphs
While our survey asked people to classify paragraphs on a 5-point scale, we collapse these labels into 2 categories – ‘high’ and ‘low’. We do this because using this binary variable generates results that are more reliable. In practice, we also used a third implicit label – ‘ambiguous’ – that applied to paragraphs in the middle that we excluded from the training data. We found that paragraphs scored in the middle were very difficult for the algorithms to classify and the noise this introduced tended to degrade overall performance. Label noise is a well-known problem in machine learning and there are various techniques that have been proposed to deal with it (e.g. Karimi et al 2020). We adopt the simple technique of filtering out these ambiguous labels. More precisely, we exclude paragraphs with a normalised magnitude between −0.4 and 0.4. Excluding those ‘ambiguous’ paragraphs will reduce our sample size, but provide us with a higher quality dataset. [14] This is illustrated in Figure 8.
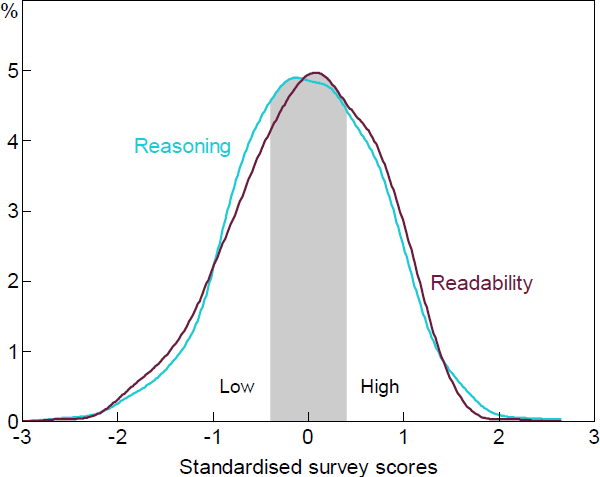
Note: Ambiguous paragraphs (denoted by the shaded area) scored between –0.4 and 0.4
5.3 Extracting text features using natural language processing
In addition to labelling our paragraphs, we need to convert the unstructured text into numerical data that can be analysed by the ML algorithms. That is, we need to compile a set of variables that numerically describe the individual paragraphs. A common approach to converting text into numeric data is using a dictionary mapping, also known as a ‘bag of words’ approach. This approach counts the frequency of particular words used in a sample of text but disregards grammar and word order. Text sentiment analysis, where the count of positive and negative words is calculated, is an example of this sort of approach.
The results using these approaches were, however, disappointing.[15] Consequently, we investigated and ultimately included more syntactic approaches. The syntactic features of a sentence, rather than the particular words themselves, can have a large effect on readability. As noted by Haldane (2017), paraphrasing Strunk and White (1959): ‘In general, the readability of text is improved the larger the number of nouns and verbs and the fewer the adverbs and adjectives’.
Therefore, we turn to a more advanced natural language processing approach that uses artificial intelligence to decompose text into its grammatical components. More specifically, we map each word in a sentence into a part of speech (PoS) using a PoS tagger and label each phrase using a parse tree.[16],[17]
As an example, we can decompose the sentence ‘The cat sat on the mat because it was warm.’ into a syntax tree as shown in Figure 9. It identifies ‘The’ as a determiner (DT), ‘The cat’ as a noun phrase (NP), and ‘because it was warm’ as a subordinate clause (SBAR) introduced by the subordinating conjunction (IN) ‘because’. We then use counts of the various parts of speech as our variables of interest. You can see the full list in Appendix B, along with an example of how a particular sentence is converted to numerical data.
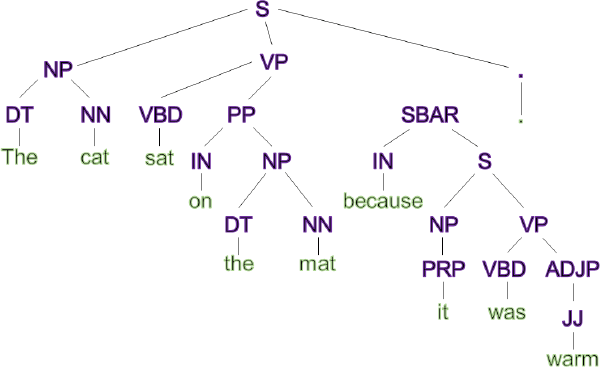
Footnotes
For the readability model, 320 sample paragraphs are removed, 264 paragraphs are labelled as high, and 241 as low; for the reasoning model, 326 sample paragraphs are removed, 248 paragraphs are labelled as high, and 251 as low. [14]
We tested model performance using a number of approaches, such as counting words (after removing stop words and lemmatisation) and mapping words to a clue words list, but found the model accuracy was not good enough to make any reliable predictions for out-of-sample data. [15]
We use the openNLP package in R (Hornik 2019) for this exercise. [16]
Bholat et al (2017) deployed a similar approach to analyse central bank communication. [17]