RDP 2023-06: Firms' Price-setting Behaviour: Insights from Earnings Calls 3. Index Construction
September 2023
- Download the Paper 1.6MB
We construct several sentiment indices from the text of each earnings call: (1) an input-cost sentiment index (including input cost subindices, such as that for labour costs); (2) a demand sentiment index; and (3) a final price sentiment index.[2]
To construct the indices, we use two approaches. The first is dictionary-based. We construct transcript-level sentiment indices by simply looking up specific dictionary terms in each of the earnings call transcripts. These dictionaries are put together in consultation with expert staff from the Reserve Bank of Australia's ‘Prices, Wages and Labour’ team. We also add additional ‘missing’ words to some of the dictionaries after training a word embedding model (Word2Vec). For example, the word ‘debottlenecking’ was originally missing from our general input cost dictionary but was added after embedding the word ‘bottleneck’ and using the embedding space to find semantically ‘nearby’ terms. After finalising the dictionary, we then conduct a proximity search anywhere within the sentence in which the dictionary term appears to look for qualifiers that indicate an increase or a decrease. After identifying the specific words in connection with their qualifiers, we sum the ‘hits’, take the balance of references to ‘increases’ and ‘decreases’, and divide it by the total number of words in the transcript. In total there are 70 terms related to input costs in the dictionary, which can be mapped into 10 input cost subindices (see Appendix A for details). We also develop separate dictionaries for consumer demand and final prices.
Specifically, letting Wit = [w1,w2,w3,...,wn] be a list of the words (with repetitions included as separate elements) used in firm i's transcript in time t, and Sit =[s1,s2,s3,...,sn] be the list of sentences, the dictionary-based sentiment index, DS, is calculated as:
where is the indicator function that is equal to one if the associated condition is met. Here, for a given sentence, s, and word, w, we record a positive contribution to the index if the word is a member of the relevant dictionary d, , and there is a qualifier in the selected sentence that indicates an increase, , without an offsetting negative qualifier that indicates a decrease,.
To illustrate the methodology, Table 1 includes random examples underlying the construction of the general input cost, labour cost, demand and final price indices.
| Company | Sentence | Relevant index | Keyword and qualifier |
|---|---|---|---|
| BlueScope Steel | Question: First of all, seeing a lot of publicity about the, not only the cost increase for EAF electrodes, but a great shortage and people struggling to get them. | General input costs | cost + increase |
| Commonwealth Bank | Prepared remark: However, because we're now doing better and because the economy is improved, we've passed on a 2% wage increase to our staff with effect from 1 January. | Labour costs | labour cost + increase |
| BHP Group | Prepared remark: In the past year we've continued to see demand for our products remain strong. | Demand | demand + strong |
| Tabcorp | Response: And with the price increase, all of the dividends through all of the divisions will increase commensurate with the price increase. | Final prices | price + increase |
|
Sources: Authors' calculations; Reuters |
|||
The benefit of the dictionary-based approach is that it is completely transparent. However, the process of developing dictionaries is manual and has several limitations. First, the dictionaries we develop are non-exhaustive, giving rise to many missed ‘hits’ or false negatives. Second, the simple dictionary-based approach does not capture semantic meaning, potentially giving rise to a significant number of false positives. Finally, as different companies use different specialised language it is difficult to develop a uniform dictionary, which could potentially generate inconsistent results. Ultimately, selecting an optimal set of keywords is a near impossible task and can bias inferences (King, Lam and Roberts 2017). For this reason, we use results from the dictionary-based approach in this paper as a crosscheck on those we obtain from a large language model.
Our second (and preferred) approach draws on a new generation of machine learning based large language models to uncover semantic meaning, which we use to identify when company executives are talking about our topics of interest. Our chosen topics of interest cover: hiring difficulties; supply shortages; labour costs increasing; labour costs decreasing; transportation costs increasing; transportation costs decreasing; import costs increasing; import costs decreasing; general input costs increasing; general input costs decreasing; final prices increasing; final prices decreasing; consumer demand increasing; and consumer demand decreasing. We parse the text of every paragraph in the transcripts (around 700,000 in total) and use the classifier to determine the probability the paragraph is about each of our topics of interest independently. The output from this process is illustrated in Figure 4, which demonstrates the model's ability to classify without finding explicit keyword matches. For example, the semantics of staff retention difficulties mentioned in the text from Australia's largest airline are captured by the model in classifying the theme hiring difficulties. In this way, we effectively reframe the dictionary-based approach into a text classification problem, enabling us to classify paragraphs without finding explicit keyword matches.
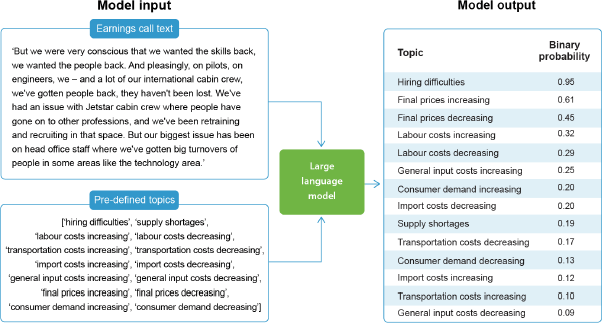
In this application, we apply a label to a paragraph if the model assigns the label a binary probability of greater than 70 per cent.[3] The sentiment index for a given topic is then calculated as the number of labelled paragraphs in a transcript divided by the total number of paragraphs. Specifically, letting p represent a paragraph from the list of all paragraphs Pit = [p1, p2, p3,...,pn] in firm i's transcript, the classification-based sentiment index, CS, for topic z, is calculated as:
where the indicator function is equal to one if there is a greater than 70 per cent probability the paragraph is about the topic of interest. The index nets off positive, , and negative, , references to a given topic.
To perform this classification, we use a class of deep learning models called zero-shot text classifiers. Zero-shot text classification refers to the ability of a model to classify text into an arbitrary set of user-chosen categories, even if it has not been explicitly trained on those categories. In other words, it can predict the correct label for a given input without any prior training data specific to that label. We use a complex 400-million-parameter zero-shot classifier developed by Facebook AI named BART-large-MNLI.[4] As the name suggests, there are two parts to the classifier.
‘BART-large’ refers to a large-scale pre-trained model called ‘BART’, short for Bidirectional and AutoRegressive Transformers. BART is based on a transformer architecture (Lewis et al 2019), which enables it to be trained at massive scale. In this case, the model develops an understanding of language semantics through training on English language free-text datasets, including the Wikipedia corpus, news and books.[5] The model's training objective is to minimise the loss associated with reconstructing corrupted sentences into their original form, learning the dependencies and context of natural language along the way.[6]
The second part of the classifier ‘MNLI’, stands for Multi-Genre Natural Language Inference. This refers to a clever training objective designed to fine-tune BART's ability to understand natural language. Following the procedure outlined in Yin, Hay and Roth (2019), BART is fine-tuned by tasking it with predicting the labels in the multi-nli dataset (see <https://huggingface.co/datasets/multi_nli>). This dataset is a crowd-sourced collection of sentence pairs from various genres, with each pair consisting of a premise and a hypothesis along with a label from one of the following categories: (1) ‘entailment’, whereby a human reading the premise would infer that the hypothesis is most likely to be true; (2) ‘contradiction’, whereby a human reading the premise would infer that the hypothesis is most likely to be false; and (3) ‘neutral’, indicating there is no discernible relationship of entailment or contradiction between the premise and the hypothesis. Fine-tuning BART to predict these class labels enables it to be used off-the-shelf as a zero-shot text classifier, as we do in this paper. We choose to use the BART-large-MNLI model specifically because it is fine-tuned for natural language inferencing.[7]
Footnotes
All of the code underlying our analysis of the earnings calls, index construction and empirical results is available in the online Supplementary Information. [2]
We used judgement to select the 70 per cent threshold after doing a number of ‘spot checks’ of the resulting classifications. An alternative approach is to create each topic-specific index by weighting each paragraph by its topic-specific probability. We use a threshold because our first priority is to minimise false positives, recognising this comes at the cost of not utilising all of the available textual information. Regardless, at an aggregate level, the results from both approaches (using a threshold or probability weighting) are very similar. [3]
This model is available on Huggingface (see <https://huggingface.co>). Huggingface is an open-source library for NLP providing a wide variety of transformers and models for text classification, text generation, sentiment analysis, named entity recognition and more. [4]
The pre-training does not include any earnings call transcripts. [5]
Lewis et al (2019) corrupt text snippets in the following ways: (1) token masking, where random words are replaced with blanks; (2) token deletion, the same as (1), but the model must decide which positions are missing inputs; (3) text infilling, where spans of text are filled with a blank; (4) sentence permutation, where sentences in a text snippet are randomly shuffled; and (5) document rotation, where a random word from the text snippet is cut and pasted into the opening position of the text snippet. [6]
Other large language models would be more suitable for other tasks. For instance, while ChatGPT's underlying generative pre-trained transformer-based models have the same underlying architecture, they are trained to generate coherent and contextually relevant text, making them more suitable for generating conversational responses. [7]